
AIツールの「誤った使用法」が逆に生産性を落とす

パワーポイントの二の舞いに?
2024.01.04
by 中島聡『週刊 Life is beautiful』
全世界の人間の生活に大きな「革命」を起こしたと言っても過言ではない人工知能。その技術革新について、「これまでのどれとも大きく異なるものだと確信している」と、Windows95を設計した日本人として知られる中島聡さんは、人工知能の現状とこれからについて詳説。
さらに生成AIを巡る「2024年の傾向」を予測。
人工知能の今とこれから
2024年の最初のメルマガ、ということもあるので、現時点で最も注目すべき技術である人工知能について、現状と今後の展望について書いてみたいと思います。
この分野はこれまでの技術とは桁違いのスピードで進化をしているため、それぞれの分野の最先端がどこにあるのかを把握し続けるのすら難しい状況になっていますが、最低限、おおまかな流れぐらいは把握しておくことが重要です。
私はこの業界と40年以上関わっており、GUI、インターネット、モバイル、などの様々な技術革新を目の当たりにして来ましたが、今回の技術革新は、これまでのどれとも大きく異なるものだと確信しています。
ソフトウェアの作り方が根本的に変わりつつあり、それがオープン・イノベーションと相まって、これまでにない指数関数的とも言えるスピードで、さまざまな技術革新が日々、起こっているのです。
その根幹になるのが、Andrej Karpathyが2017年に提唱した「Software 2.0」で、それが何を意味するのかを理解して初めて、今起こっている技術革新が何なのか、そして、どんなインパクトをこの業界だけでなく、社会全体に与えるのかをイメージできるようになります。
Software 2.0とは、ひとことで言えば「人間(ソフトウェア・エンジニア)がちまちまとアルゴリズムを組み立てる時代から、ニューラルネットワークを活用して、マシンそのものにアルゴリズムを作らせる時代」を意味します。
誤解してほしくないのですが、これは(OpenAIのCode Interpreterのように)マシンがコード(プログラム)を生成する時代の話をしているのではありません。
莫大な数のパラメータを持つニューラルネットワークが、機械学習の結果、人間が作ったアルゴリズムやコードの代わりに、問題を解決してしまうことを意味します。
一昔前まで、画像認識は人間が作ったアルゴリズムを活用して画像に含まれたさまざまな特徴を認識し、そこに写っている物を認識したり、位置を特定したり、ということをしていました。それには莫大な手間(プログラミング)がかかり、かつ、作ったプログラムはすぐに陳腐化してしまう、という欠点を抱えていました。
ニューラルネットは、その「手間」をマシンに任せることを可能にしたのです。
ソフトウェアを人間が作っている限り、その開発スピードには限界があります。
そもそも優秀なエンジニアの数は限られているし、一人のエンジニアが1日に働ける時間も限られています。
一つのプロジェクトに関わるエンジニアの数が増えると、どうしても生産効率が悪くなってしまいます。
10人のソフトウェア・エンジニアを雇ったからと言って、10倍のスピードでソフトウェアを生産できるわけではないのです。
ソフトウェアの規模が大きくなると、複雑さが増し、全体を理解することが難しくなり、最終的にはメンテナンスが不可能になり、陳腐化してしまいます。
ニューラルネットを活用したソフトウェア・エンジニアリングは、そんなソフトウェアの作り方を根本から変えました。
ニューラルネットの設計そのものは人間がしていますが(少なくとも今の時点では)、作ったニューラルネットワークの中の莫大な数のパラメータを更新する仕事はマシンが行います。マシンは24時間連続で働かせても文句も言わないし、コストにさえ糸目をつけなければ、何万台、何十万台という数のマシン(GPU)を並べて、同時に働かせることも可能です。ニューラルネットの設計さえ良くできていれば、10倍のマシンを使えば、10倍の効率で仕事をしてくれます。
パラメータの数に関しても同じです。
パラメータの数を10倍に増やしたからと言って、(人間が作るプログラムのように)複雑さが指数関数的に増して破綻するようなことはなく、それに見合っただけの能力を発揮してくれるのがニューラルネットの特徴です。
ニューラルネットは、オープンな形のイノベーションとも相性が良いのです。
人間が作る(何十万行にも渡る)ソフトウェアと違って、ニューラルネットの設計そのものははるかにシンプルなので、それを論文やオープンソースな形で公開し、それをお互いに活用しながらイノベーションを起こすことが可能だし、それが常識になっているのです。
それどころか、作ったニューラルネットに莫大な量の学習データを与えて機械学習させて作ったパラメータそのものを公開する研究者すら現れており(Metaがリーダーシップ的な役割を果たしています)、それがさらにイノベーションを加速している点は注目に値します。
とは言え、ニューラルネットに適したものとそうでないものがあるので、全ての場合にニューラルネットが適用できるわけではありませんが、研究者たちの努力により、ニューラルネットが適用できる範囲が増えており、近い将来に多くのアルゴリズムがニューラルネットに置き換えられると考えて良いと思います。
ニューラルネットが面白いのは、複数のニューラルネットから構成されるソフトウェアがあった場合、それらを一つのニューラルネットとみなして機械学習をさせることが可能な点です。
Teslaの自動運転システムは、深さ検知、物体認識、経路選択などの複数のモジュールで構成されており、当初は人間が手作業で作ったモジュールと、ニューラルネットで構成されたモジュールとが混在していましたが、v12から全てのモジュールをニューラルネットで置き換えることに成功したため、自動運転システム全体を一つのニューラルネットとして同時に機械学習させることが可能になったそうです。
そんなことが可能なのは、ニューラルネットの学習に使われているバックプロパゲーションという仕組みによるものです。
バックプロパゲーションとは、複数の関数が重なって作られた関数がある場合(例えば、y=f(g(x))に、それぞれの関数の微分係数が計算できる限り、何段階でも遡って学習(学習データに応じてパラメータを逐次更新)することを可能にする仕組みですが、各モジュールがニューラルネットで構成されている限り、モジュールの境をまたいでバックプロパゲーションを行うことが可能なのです。
Teslaの自動運転システムには、v11まで30万行の(人間が書いた)コードが含まれていましたが、v12からはその全てをニューラルネットで置き換えることに成功したそうです。
30万行ものコードが存在すると、そのメンテナンスだけで一苦労です。
コードにわずかな変更を加えるだけでさまざまな副作用が生じるため、一つのバグの修正のためのコードの変更が、別のバグを生み出したり、ということは日常茶飯事になります。また、コードを書いた担当者が辞めてしまった結果、どうやって動いているのか誰も理解が出来ず、変更を加えることが不可能になってしまったモジュールとか、数多くのモジュールがそのモジュールに依存してしまっているため、わずかな変更すら加えることが大きなリスクを伴うモジュールなどが出来てしまいます。
Teslaは、全てのモジュールをニューラルネットに置き換えることにより、自動運転システムから人間が書いたコードを排除することに成功しました。
Teslaは世界中にあるTesla車から集めた映像データを運転手の操作と共に記録し続けているため、今後は、それを学習データとして、自動運転システムを改良していくことが可能になります。
人工知能全体に関して言えば、2023年は、生成型AIと呼ばれる分野での進歩が最も目についたものです。
ChatGPTに代表されるLLM(大規模言語モデル)は、単に「次に来るだろう単語を予測する人工知能」をTransformerという仕組みを使って作ったところ、「あたかも知能がある」かのように振る舞う人工知能が出来たことから、AGI(汎用人工知能)へのアプローチとして研究者に注目が集まり、今では、数多くのモデルが作られています。
現時点で、最も性能の高いもの(SOTA: State Of The Art)は、OpenAIのGPT4ですが、GoogleからはそのライバルとされるGemini Ultraが発表されたし(まだリリースはされていません)、オープンソース側でも、その一世代前のGPT3.5に匹敵するものが発表されました。
オープンソースのLLMとしては、Metaがオープンソース化したLlama2が業界スタンダードになりそうに見えましたが、その後、フランスのMistralという会社がオープン化した、Mistral及びMixtralが現時点では、オープンソースLLMのSOTAと呼べる存在です。
しかし、この分野は、オープン・イノベーションが非常に活発な分野であり、2024年中に、Mistralの新たなライバルが現れたり、GPT4に匹敵するものが出てきても全く不思議はありません。
現在、最先端で戦っているLLMは全て、Transformerベースのもので、それが2024年中に変わるようなことはないと私は見ています。
現状のLLMは、単に「次に来るだろう単語」をひとつづつ予測しているだけなため、数学の問題のように「ちゃんと考えて答えを見つけ出す」ことは不得意です。
OpenAI、Meta、Googleなどの研究者たちは、この問題を解決するための仕組みづくりに取り組んでいますが、非連続なイノベーションであるため、そんなブレークスルーが2024年度中に起こるのかを予想するのは不可能です。
OpenAIの取締役会がSam Altman CEOを解雇した理由の一つとして、そんなブレークスルーがあったという情報もありますが、それも噂に過ぎません。
さらに、莫大な学習データを必要とし、かつ、学習後の質疑応答から何も学ぶことが出来ない人工知能は、人間の頭脳と比べて随分と劣りますが、その問題の解決も不連続なものになるため、いつ起きるのか、そして、それがどんなアーキテクチャになるのかを予想するのは現時点では不可能です。
とは言え、私のような開発者(エンジニア)の仕事は、既存のLLMの活用にあるため、大半の開発投資は、Fine Tuning(必要な分野の学習データでモデルを改良すること)やRAG(Retrieval Augmented Generation: 質問に応じるのに必要なデータをコンテキストとして与えてLLMに応えさせること)などに費やされることになります。
オープンソースなLLMによる推論をいかに効率良くさせるか、という研究開発も素晴らしい勢いで進んでいます。
Mixtralが採用したMOE(mixture-of-experts)という仕組みは、(LLMの性能を上げるために)モデルのパラメータを増やしながらも、推論時に必要な計算量を節約する手法で、(公式には認められていませんが)GPT4でも採用しているとされています。
(サーバーではなく)ノートパソコンやモバイル端末でLLMを動かすための仕組みも徐々に整い始めており、オープンソースとして公開されたモデルのQuantization(量子化)はコミュニティによって行われているし、Appleが最近になって公開したMLX(Apple製のチップ上で、ニューラルネットによる推論を効率良く実行するライブラリ)にもすぐにコミュニティが作られて、オープン・イノベーショが起こっています。
Llama2やMitralなどのオープンなLLMが、スマートフォンやVR\ARグラスで効率良く走るようになり、それが実際にアプリケーションとしてリリースされるのは時間の問題で、2024年はそんなアプリケーションを数多く見ることになると予想出来ます。
LLMのマルチモーダル化(言語だけでなく、画像、映像、音なども扱えるようになること)も加速しており、ここに関しては、OpenAIとGoogleが先を進んでいます。
マルチモーダル化がオープンソース側に起こるのも時間の問題とも言えますが、文章と違って、著作権に縛られない学習データだけで優秀なマルチモーダルなLLMを作るのは難しいため、それがボトルネックになる可能性はあります。
ちなみに、著作権問題は実際にはテキストデータにも適用される話なので、今後はLLMの開発メーカーがメディアから著作権付きのテキストを学習データとして購入する、という方向に動く可能性が高いので、これには注目する必要があります。
オープンソース側は、どうしてもそこが弱いので、それが勝負の分かれ目になってしまう可能性も否定できません。
Xが後発でありながらも、「Grok https://grok.x.ai/」というLLMをリリースしたのは、X上のテキストを学習データとして利用できるという、Xならではの利点を活用したものです。
Grokは、Primium+ユーザーにしか使えないので、市場全体に対するインパクトは大きくありませんが、今後の展開次第では、面白い存在になる可能性を秘めています。
上では、主にLLMのことばかり書いてきましたが、画像・映像・音楽の生成形AIに関しても素晴らしいペースで進化が起こっています。
当初は、OpenAIのDall.E、Midjourney、(オープンソースな)Stable Diffusionの三つ巴の戦いでしたが、Meta、Adobe、Google、Microsoft(バックエンドはDall.E)が参戦し、一気にコモディティ化した感があります。
とは言え、最近v6 にアップデートMidjourneyは、表現力が大きく上がったようで、高品質な作品が数多く投稿されています。
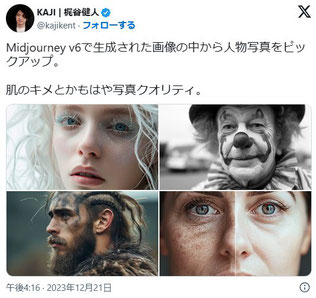
一つ心配なのは、Midjourneyは明らかに著作権法で守られている作品を使って機械学習をしている点で、「ドラゴンボールの孫悟空」というプロンプトを入力すればそのままの画像を作ってしまいます。

消費者は喜びますが、ここまで露骨にやってしまうと著作権法のボーダーラインを超えたと解釈されても仕方がないと思います。
これらの画像生成系AIで生成した画像を「RunwayML」、「Pika」、「Stable Video Diffusion」のようなImage2Videoを使って動画にしたり、AIを使った音声やAIにより自動生成された音楽を組み合わせて、本格的な映像を作り出すアーティストまで現れたのが2023年の特徴とも言えます。
最近、ウクライナのキーウのアーティストMykhailo PenievskyiがAIを活用して作ったショートフィルム“Phantom Christmas”が、“AI Holiday Film Competition.”で3位に入賞したという報道がありましたが、今後、そんな作品はますます増えると予想出来ます。
動画作成に関しては、「CreativeEdge」という方が日本語でnoteに連載を書いているので、興味がある方は覗いてみると良いと思います。
しかし、たとえAIツールを使おうとも、良い作品を作るにはそれなりの才能と努力が必要で、結局のところは「AIを上手に使いこなすアーティスト」の生産性が極端に上昇し、この手のツールの使い方を学ぶことを厭わない人と、そうでない人との差が大きく開くのが2024年の傾向であろうことは明らかです。
ちなみに、これらのAIツールはとても便利ですが、使い方を間違えると逆に生産性を落とすことになるので要注意です。
Microsoftのパワーポイントはとても便利なツールですが、パワーポイントが出来たおかげで、逆に資料作りに妙に時間がかかるようになった人も多いのも事実です。
生成系AIが面白いからと言って、必要もないところにまでAIで作った凝った画像や映像を貼り付けるようになったら本末転倒ですが、そんな無駄がたくさん起こるのも2024年の特徴だろうと思います。
また、生成系AIを活用した、フェイクニュースが横行するのも2024年の特徴なので注意が必要です。
生成系AIを活用して捏造された画像や映像の真偽を見極めることは難しいし、かといって、それほど広まってはいないため、まだまだ多くの人々が騙されることになるのが目に見えています。
その意味では、2024年の米国大統領選挙の結果が、フェイクニュースによる世論操作の影響を大きく受ける可能性はとても大きいと思います。
誰が大統領選の候補になろうが、それぞれの人物が登場する数多くのフェイク画像と映像が作られることは確実です。
(『週刊 Life is beautiful』2024年1月2日号の一部抜粋。


最後までお読みいただき、有り難うございました。 ☚ LINK
*** 皆さんからの ご意見・ご感想など 『
※ メール・BLOG の転送厳禁です!! よろしくお願いします。
コメントをお書きください