

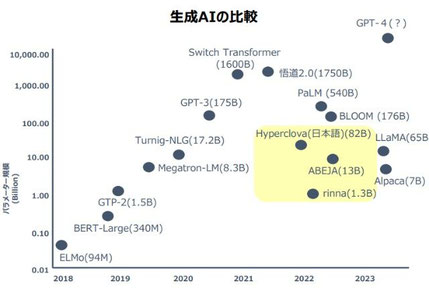
基盤モデルの学習では、桁違いのGPUを使用
基盤モデルや拡散モデルといった高度なAIモデルを活用するには、ディープラーニング以上の演算能力を要する。
生成AIサービスを提供する企業にとって、こうした莫大な演算能力をいかに最小限の投資で用意できるかがビジネス化するうえでの重要課題になる。
従来のディープラーニングでは、GPUを数個搭載する規模のサーバーで学習処理を実行できた。これが基盤モデルを学習する際には、少なくとも千個以上の最新のGPUを数カ月間動かし続ける必要があるという。そして、GPT-3ならばGPUを数千個、GPT-4では3万個超を使用していると言われている。特定タスク向けにカスタマイズするファインチューニングでも、基盤モデルの学習に比べれば処理時間ははるかに短いが、同様の演算能力が必要になる。
こうした高性能を実現するコンピューターを企業が自社保有して、生成AIサービスのビジネスや基盤モデルを活用したアプリケーション開発を展開するには、巨額の費用と投資回収が見込める使い先の確保が必須になる。
たとえコンピューターを保有しないまでも、少なくとも基盤モデルをファインチューニングする作業以降は、各企業個別で行う必要がある。学習データに秘匿性の高い社外秘データなどを大量に扱うことになるからだ。
そこで大手IT企業のなかには、極めて汎用性の高い共有基盤モデルを用意し、ファインチューニングだけの高度なAI環境を提供するところが出てきている。米IBMの「Watson X」はこうしたサービスの代表例である。
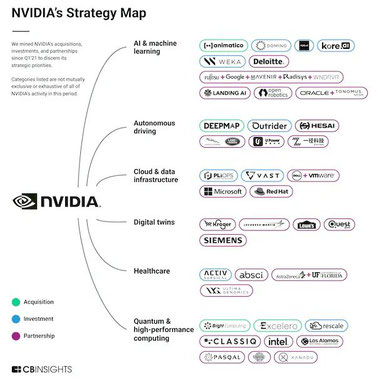
CBインサイツのデータを活用し、エヌビディアの21年以降の買収、出資、提携から6つの重要戦略をまとめた。
この6つの戦略でのエヌビディアとのビジネス関係に基づき、企業を分類した。
・AI&機械学習
・自動運転
・クラウド&データインフラ
・デジタルツイン(仮想空間に現実のモノや空間を再現する技術)
・ヘルスケア
・量子コンピューティング&ハイパフォーマンスコンピューティング(HPC) @日経新聞

※ メール・BLOG の転送厳禁です!! よろしくお願いします。
コメントをお書きください